
On time: filtering, find & replace
Practical examples for English, with some German and Portuguese flavoring

For an expert in regular expressions, it’s a fairly easy thing to build an auto-translation ruleset in memoQ that takes some usual formats of time expressions in one language and converts them to a specified format in the target language. Here’s an example in that horrible, integrated rule editor in memoQ:


These rules will do a fine job of mapping an expression like 3:15 a.m. to 3h15 if you like, and we’ll skip the discussion of all the similar cases where the rules will fail. (These were some quick rules drafted for use in a class where the shortcomings and remedies were discussed. I’ll do something similar later in a separate post that is actually about auto-translation rules.)
However, as we saw in the first article in the series on time expressions, time expressions aren’t always so neat and standardized in format. Here are a few more examples of that in some random hits I pulled off Linguee:

Some of these examples will give you false error warnings if you foolishly use memoQ’s QA checks with number checking enabled. (It’s best to avoid this in nearly all cases as I’ll explain in separate posts on memoQ quality assurance. Often, a lot of time wasted dealing with false positives can be avoided by proper regex-powered checking.)
Despite all the enthusiastic promotion of LLM-based quality checking, I have serious doubts that such tools would be able to identify and correct problems involving varied time formats. I invite anyone so inclined to prove me wrong. One of the problems, I think, would also be defining exactly what one wants for the translated format. That may depend on the applicable style guide or even just a good sense of style. But rules which can be defined clearly can in fact be constructed and used in automated QA. This might take some serious time.
There are a number of useful waystations on the path to that goal, and for some these may be entirely satisfactory destinations. Not only is there a certain emotional satisfaction to staying involved in the QA inspection loop at the level of the translation and editing grid, but when executing filtering commands and performing find & replace operations to fix errors, additional cases not considered are often found. Time spent examining your translation texts and translation memory resources this way is seldom wasted. Often when I inspect the TM resources of an LSP I find hundreds of errors (or more) in content that came from approved trashlations (caveat emptor).
So let’s consider some regexes which can help us identify time expressions and perhaps correct some common deficiencies. I’m going to include a few nerdy bits in explanations for those who care about such things, but I invite you to ignore those details, as all that regex will be collected as named expressions with labels and descriptions and made available in XML format as a downloadable Regex Assistant library export, so you can
just import the expressions to your own library and use them,
modify or extend the expressions as you please in your library, or
do an XSLT on that library export to make a nice HTML file that you can use easily in environments other than memoQ.
That last point will be the subject of an article on another day, in which I talk about other conversions involving exports from term bases as well, but for those of you who are impatient and want to do such things now, here’s my PDF cheat sheet to get you there:
I’m going to divide the examples by language. They don’t cover all cases, but they should give you a good start and an idea of what other things may be possible. We can discuss those possibilities in the comments for this article, a public chat thread or private messages if you feel like exploring other possibilities and solutions. The library exports for the examples are included as downloads at the end of this article for paying supporters of this education project.
I’m also going to use my favorite web page for testing regular expressions, the Regex Storm .NET Regex Tester, to illustrate some of the examples, because I find its use of alternating colors for hits and the tabular presentation of group values to be extremely helpful. I use this page a lot to study difficult regex problems.
English time expressions
The most obvious examples to look for are numerical ante meridiem or post meridiem time expressions: some number(s) for time + some form of AM/PM. Because of all the different ways these can be typed, and, if you deal with English texts written by non-natives like I do, the possibility that the formats will not be the ones you expect, and because capitalization may vary, the regex can get a little complex. In my introduction to time expression handling, I used this:
\d{1,2}(.\d{2})?\s(?i)[ap]\.?\s?m\.?\b
Let’s break it down. Think of three-thirty in the afternoon. That might be written as 3:30 PM. Or 3:30PM. Or 3:30pm. Or 3:30 p.m. Or 03:30 P.M. Or a number of other ways. How do you capture all of these possibilities in one expression. And also deal with the German authoring in English who writes 3.30 p.m. or the Portuguese who doesn’t realize that 3h30m isn’t usual in English? Hmmm… that last one… we’ll see. First of all, I’m going to copy all these to my favorite web page for testing:

As you can see, I’m already out past my skis with that last expression. And if there’s no space after the numbers it also doesn’t work. But fear not, I can edit the regex.

But what about 3 ambulances? Whoops!

So one more change….

And all is right in Wrightsville. What the heck was going on with all those edits, and what does it all mean? My changes were:
moving
(?i)to the front of the expression. That’s a switch to make the match case-insensitive, and the position doesn’t matter in this expression. I just moved it so I could focus better on the parts that did need changing.making the space after the number(s) optional by adding a question mark

That fixes things for the first two time expressions that were missed and was also necessary for that deviant Portuguese-style expression to be caught.
I made the
[ap]list which makes the first part of AM or PM optional. Because Portuguese.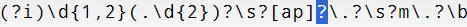
And I found that if I didn’t leave the
\bword boundary at the end I would be chasing 3 ambulances with my matching.


The final expression can be read as “case insensitive, one or two numbers, possibly followed by any character and two more numbers, possibly followed by a space of some kind, possibly followed by either an “a” or a “p”, possibly followed by a period, possibly followed by a space of some kind, definitely followed by and “m” and then possibly another period, then here we are at the word border so that “m” can’t be part of some word”.
Don’t worry about all that crap. Just know that (?i)\d{1,2}(.\d{2})?\s?[ap]?\.?\s?m\.?\b is a pretty robust way to find AM/PM time expressions, though of course it’ll fail if you run into stuff like “He came by at two PM” if some idiot writes like that. There are ways to deal with that too
(?i)(one|two|three|four|five|six|seven|eight|nine|ten|eleven|twelve|ty|een|\d{1,2}(.\d{2})?)\s?[ap]\.?\s?m\.?\b
but maybe we don’t want to go there on a hot day like today.

Whoops. Well, what’s done is done. God help us if it’s two in the afternoon or seven thirty in the evening or nine-fifteen at night. You really can overdo these things.

Hmm. Well, I guess that one expression covers the other time examples I wanted to do for English. So into the Regex Assistant library it goes. If you have others of interest, put them in the comments.

Whoops! I forgot about all those o’clock expressions! Well, I can edit that regex in my library before I export it to share.
Let’s say you have a text that has been worked on by a whole team of uncoordinated monkeys, each of which types time expressions differently. So you’ve got a lot of stuff like 2am, 3:30 p.m., 7.15 PM and 15h30 P.M. because monkeys. And your style guide calls for the format of numbers with a colon separating hours and minutes, and a non-breaking space between the number expression and a.m. or p.m. (written lowercase with periods). Oh yeah, and this is 60,000 words for you to review, and you have two hours to grind that linguistic sausage and turn it in because the monkeys finished the job three days late. Suicide is not an option, and you’ve already lost your mind.
Interesting challenge, that. Let’s see what we can salvage. There are many ways to boil this rotten potato.
I suppose I would deal first with the output from the monkey who doesn’t realize that AM/PM doesn’t go with a 24-hour clock. And maybe while I’m at it, I’ll make sure that the team actually understands that 12 a.m. is midnight, not noon. (Spoiler alert: many monkeys don’t know that, and will often incorrectly write some version of 12 p.m. for midnight.)
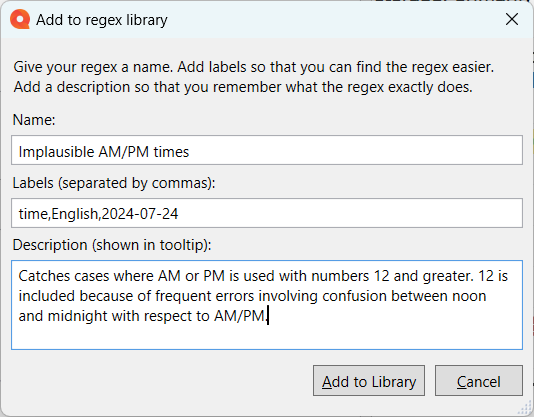
A candidate regex for that might be (1[2-9]|2[0-4])(.\d{2})?\s?[ap]\.?\s?m\.?\b
Close only counts in horseshoes and hand grenades. A bit of time on the test page led to a better candidate:

That expression catches implausible AM/PM time expressions without nitpicking the separator for hours and minutes and also anything involving an hour of “12” so it can be confirmed by inspection that the translator wasn’t confused between midnight and noon. Into the library with it!
Now what about the other parts of that mess? Inconsistent AM/PM formatting, the need for a non-breaking space between the numbers and AM/PM and fixing cases where some character other a colon is used to separate the hours from the minutes?
I could do this with an auto-translation ruleset, but that’s fodder for another day’s horse. Now it’s time for some find & replace regex. The test page can help us with that too… with some limits.
Because I’m tired and haven’t got any better ideas, I’ll do this in two stages. First for time expressions with no minutes, and then for those with minutes.

And the table on the test page tells me that the numbers I want are in Group #1 (i.e. $1):
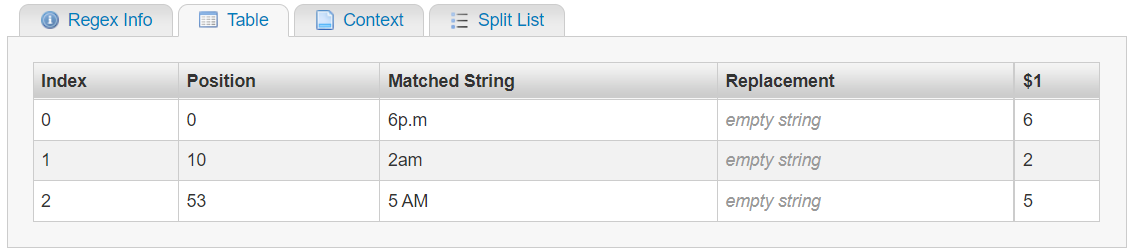
So far, so good. But… since we’re building an expression set to find & replace the AM/PM times, I’ll have to do AM and PM in separate passes:


And then the same thing with $1 p.m. to fix things like that “6p.m.”.
Same process for the times with hours and minutes, for example:


Did you catch that clever bit of lead zero stripping? I love that trick:
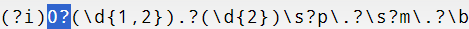
Now what about those non-breaking spaces? Trust me, they are there. But there’s no way to show non-printing characters in the browser where I used the test page, and non-printing characters also cannot be seen in memoQ find & replace dialogs nor in Regex Assistant dialogs in the current version of memoQ (11.0.20) and past versions. So non-breaking spaces must be pasted or typed manually in those environments and treated with care, as there is no visual clue to tell them apart from ordinary spaces until the results are in the memoQ working grid or a program like Microsoft Word with the non-printing character display turned on.

Now there’s a small problem. Replacing the first match (highlighted in orange) causes a doubling of the period, which we don’t want. So we have to capture any periods after the AM/PM expressions with the find expression. That is also clear from the second match (highlighted), which hasn’t been replaced yet. (And of course this applies to the regexes for expressions that don’t have minutes!) So…

All is apparently well now. At least this is what’s going into my Regex Assistant library.
But where the heck did that \u0020 come from in the Find expression? It’s the Unicode designation for an ordinary space. I wanted the Find expression to skip any time that already had a non-breaking space. Maybe that’s not a good idea if there are AM/PM time expressions where there is already a non-breaking space but your AM/PM formats are a dog’s breakfast. Your call, based on the text in front of you. If that’s the case, go back to using \s instead of the \u0020 Unicode.
Wow. Congratulations if you made it all the way on this marathon march through times. The narrative of this article realistically reflects the usual back-and-forth process of building useful, robust regular expressions for translation work, with the kind of considerations that apply nearly every time I make them for my work or am called upon to help somebody who needs this kind of expertise.
The good news for you is that the hard work is done, and if you want those expressions to use yourself, all you have to do is retype them or, if you are a paid supporter or have full access for other reasons, download the library resource at the end and import it into your own Regex Assistant library.
Of course, a similar approach can be followed for any language, and I’ve gone through it for a few. If you’re inclined to do that yourself, a wise move would be to buy one or more of Anthony Rudd’s excellent regex books for translation work (read those and you’ll understand why I used a lookbehind in a few cases). Or engage an expert to help you, one who knows memoQ inside-out. Marek Pawelec is always a good choice.
When I started the memoQuickies Substack, I wrote something about providing concise guidance. When you are confronted with an article of this size, it’s fair to ask what the Hell I mean by concise. Well… reading and applying this article is still way faster than scrolling manually through a 50,000 word project to fix problems like the ones described. Will that do for a definition?
And now for that Regex Assistant library export you can download and add to your own memoQ installation:
Keep reading with a 7-day free trial
Subscribe to memoQuickies Substack to keep reading this post and get 7 days of free access to the full post archives.