

To my traditionalist Mexican colleague who asked about regex for finding date information on stelae and other ancient sources, I have to say that perhaps memoQ isn’t the right tool for that job. But for most other date-related challenges, it may be.

Trigger warning: there is some scary regex syntax ahead. You don’t need to learn any of it. If you’re a paid subscriber or have a comped subscription, you can just skip to the bottom, download the example regexes for your personal library and have done with it!
Early last month, I published a post about auto-translation rules for dates in English source texts, with working resource examples into many other languages. Anyone who actually looks at those rulesets will notice, however, that the different downloadable examples do not all look at English dates the same way.
The reason for this, obviously, is that we encounter dates in different ways in different texts. I think all of those rulesets cover long dates in US and UK formats, but some allow less usual forms of month and day expression in those long days: instead of just forms like 15 August 2015, perhaps also “this 15th day of August, 2015”, and if someone has to deal with silliness like “this 15th day of August in the Year of Our Lord 2015” that’s manageable too.
And some texts offer a lot of month plus year expressions or day plus month with no year mentioned. Rules that include those options were written for actual projects where there were QA checks needed for those date forms.
But how do you know what rule scope you’ll need for checking all the myriad dates in that huge document you must review and deliver in such a short time? A regex screening approach using the source and target text filters of the translation and editing grid is extremely helpful to determine that, and may avoid embarrassing oversights. Much like I described for time expressions.
Having such a set of filtering and find & replace regexes (the latter to be discussed another time), preferably in your Regex Assistant library, can make it a simple matter to identify British-formatted dates in a text intended for American audiences, for example, or can avoid the embarrassment of Austrian month names in writing intended for a German audience. It can also help you determine quickly (as in my case) which of the dozens of rulesets in your collection are right for a particular job.
Once again, I will present my examples in English, because everyone reading this article presumably deals with that language in some way, if only in reading for personal enrichment, but I do have quite a few resources for other languages like Portuguese, German, Hebrew, Ukrainian and so on, so if you have particular needs and aren’t sure how to handle them, don’t hesitate to ask in the comments for this article or in some sort of private message (or in the Translation Tribulations QA thread) and I’ll do my best to help you.
Before I get into the details of my personal regex library, however, I want to digress and explain something important about how the filters of the working grid function. This may help you to identify and correct many kinds of problems involving dates, times or most anything else if you know how to take advantage of….
Funneling with the Source and Target text filters of the translation and editing grid
The principle is fairly simple, really. Filtering performed on either the source or the target side of the grid is cumulative until the applied filtering strings or regexes are cleared.
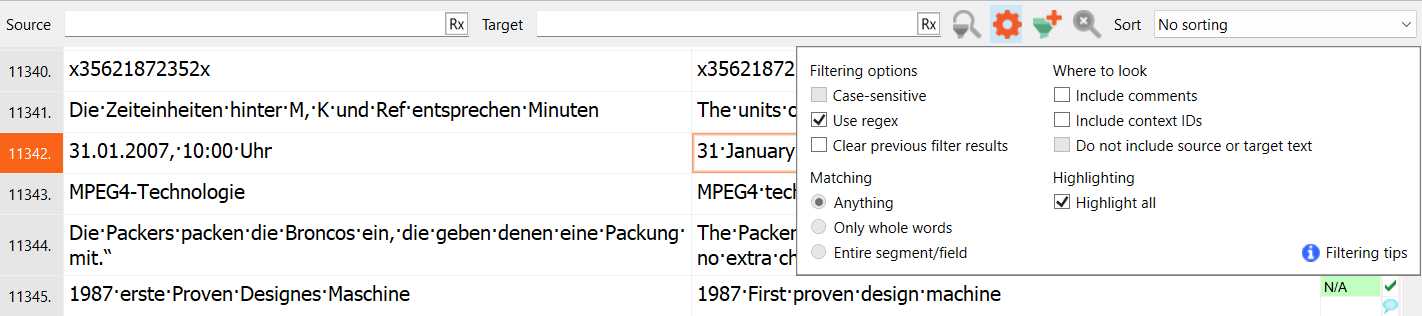
In the example below, a regex filter was applied first to the German source text to identify all months followed by a space and a four-digit number. Then the target text was filtered to find dates in US format (<month> <day>, <year>) from the segments found by the first filtration.

Now if I want to look only at the subset of the twice-filtered data that contains “October”, I would substitute that text in the filtering field for the target text:
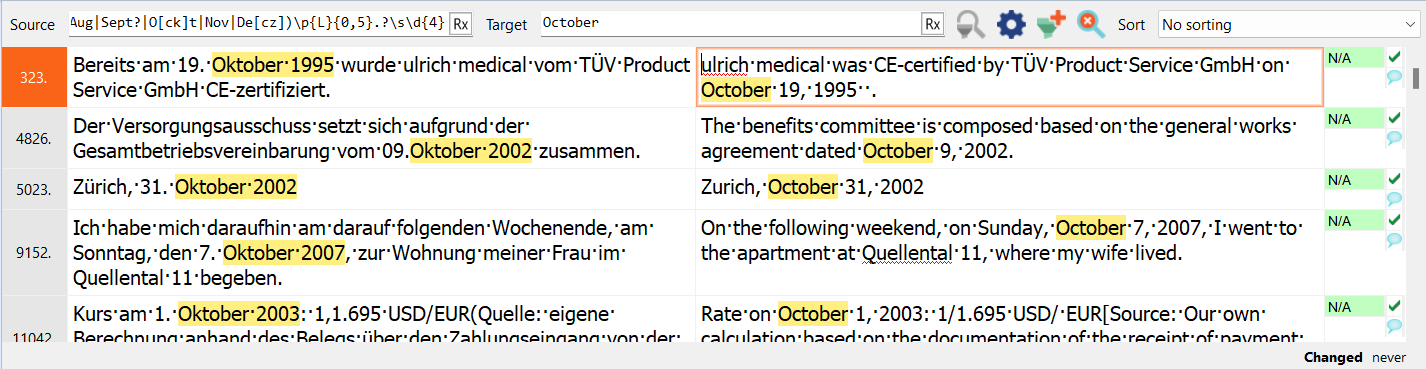
And so we get a selection of segments that have been filtered three times, each operation resulting in a smaller number of segments in the selected group, narrowing in a sense like a “funnel”.
Clicking the magnifying glass icon filled with red and an x will clear the filters.
So what kind of regexes might be useful for filtering dates?
Astute readers may have noticed that filtering commands in the examples above used a list that mixed German and English date abbreviations:
(J[aä]n|Feb|M[aä]r|Apr|Ma[yi]|Jun|Jul|Aug|Sept?|O[ck]t|Nov|De[cz])
This is one of the basic “building blocks” for date filtering that I keep in my personal library, because for more than twenty years, I translated German texts from Germany, Switzerland and Austria into various forms of English. And sometimes I dealt with crappy English texts written by non-natives who preferred Teutonic spelling in their English dates. Your situation probably differs, but be aware that you can make a multi-purpose list like this which works in more than one language, if you have such a need.
Probably a simple month list would do for a start:
(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)
Or one with the months written out, but there are some advantages to working with a list of abbreviations if there are possibly typos or a mix of abbreviations and written-out months or whatever. Up to you. You can copy and paste these examples into your personal Regex Assistant library or make up your own lists for the languages you care about.
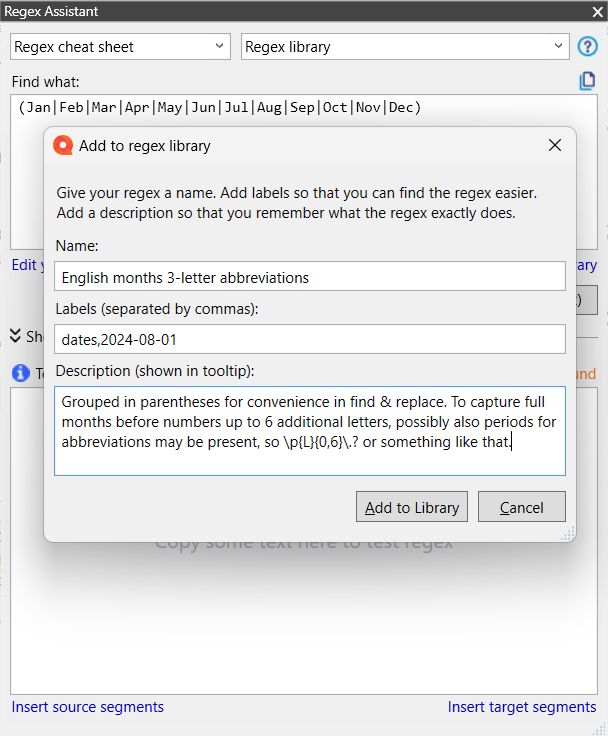
In my descriptions of regexes in my personal library, I usually include notes to remind me of frequent things I might add to the stored expression or of why I structured the expression the way I did.
And of course it makes sense to me to save a second list in the library with months fully written out, because sometimes that’s exactly what I need.
As mentioned, these expressions can be used as building blocks. If you have a text with month+year coding like APR24 for “April 2024”, you can filter to find those codes by using one of the abbreviation lists (drawn from your library) and appending regex for two digits to the list:
(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\d{2}
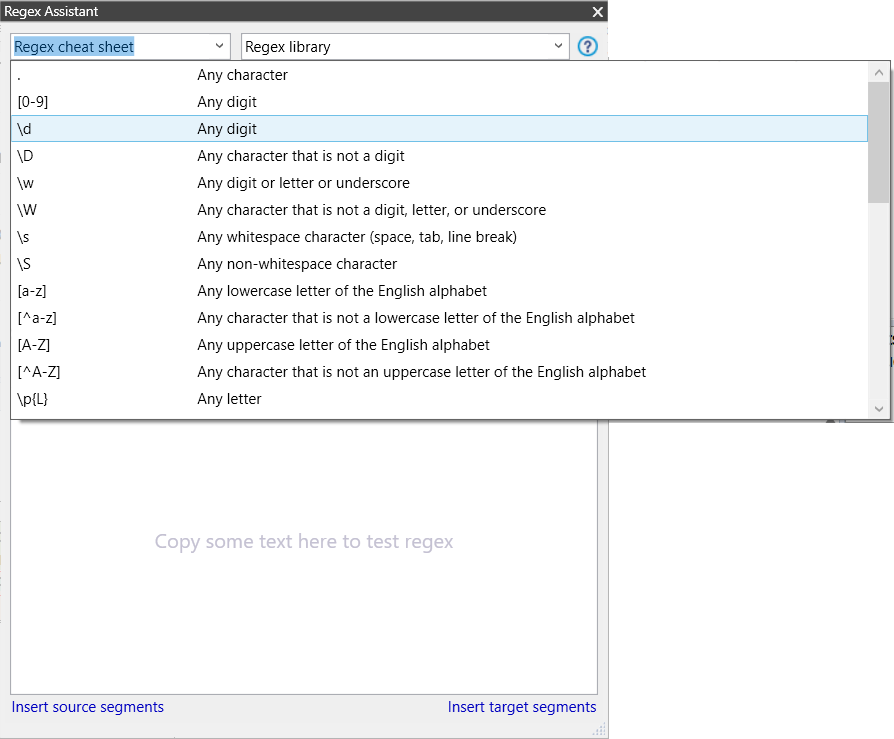
If you can’t remember the regular expression syntax for that last bit, the cheat sheet integrated with the Regex Assistant can probably help you:
But that’s all kind of nerdy and scary and whatnot, and for a start you can stick to pre-cooked regexes or have someone you trust write the ones you think you’ll need, and you just store them in your library with helpful names, labels and descriptions to remind you how to use them.
By the way, memoQ comes with quite a few prepared regexes in the Regex Assistant library, a selection by the product designers to help you with common tasks. These might also help you in many cases. Let’s have a look at what they gave us for dates:
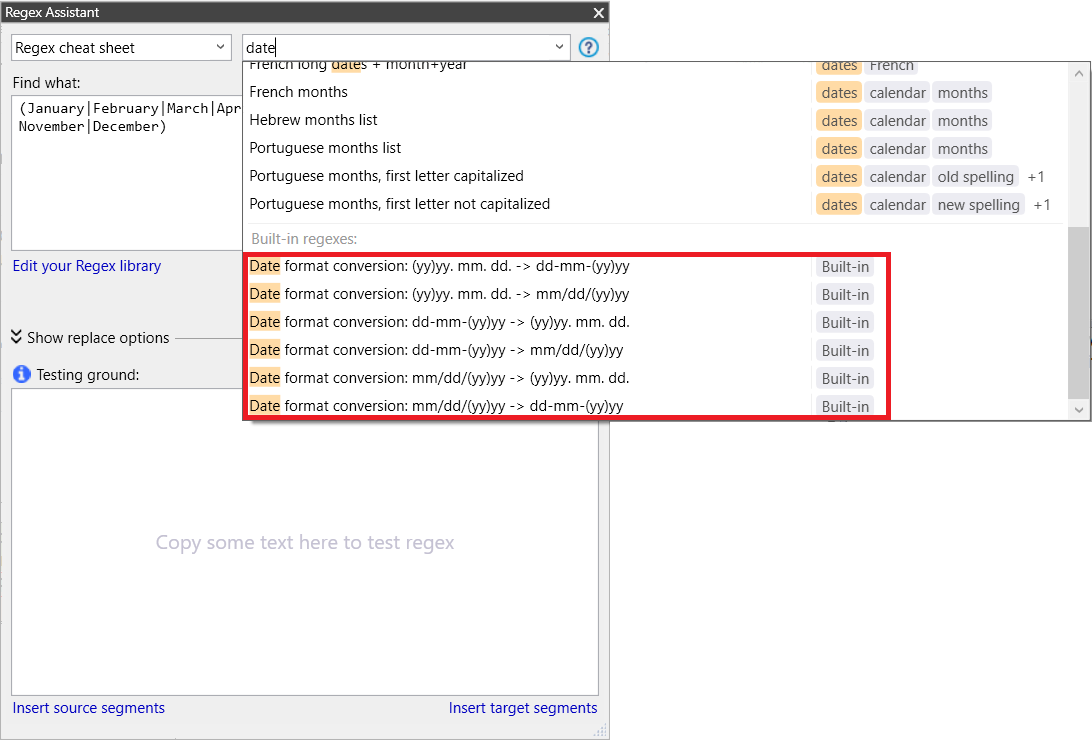
Some find & replace regexes for numerical short dates, nothing language-specific like we’re discussing now. Oh well. I’ll discuss numerical short dates another time.
One problem I have with those “Built-in” regexes is that they have neither labels nor descriptions, and I’ve seen that many users need more information to make proper use of them. I usually call the useful built-in expressions up into the editor and then re-save them with names, labels and descriptions that are helpful to me.
There are many other English date regexes that might be useful on occasion. The list could get pretty long, but fortunately you just need to record them once in your library, and they are there when you need them or when you want to use them as the basis for a new, similar expression. Some of these might be month + year:
(?i)(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\p{L}{0,6}.?\s\d{4}
It starts off with (?i) to make the expression insensitive to case.
Then you’ve got the month abbreviation list, followed by zero to six letters and possibly some other character like a comma, period or whatever.
Then whitespace. Then a four digit number (i.e. the year if things go right).
Filtered hits with that expression would include the last two parts of UK long dates like 15 September 2005. US long dates will be missed.

What if I want to exclude the long dates (i.e. where the day is present before the month)? This is where things get really scary for many people and they enter the syntactical territory of the negative lookbehind!
That horror might look something like this: (?<!(\d{1,2}\s))
And it would go in front of the month list to make sure there are no 1- or 2-digit numbers in front of that month:
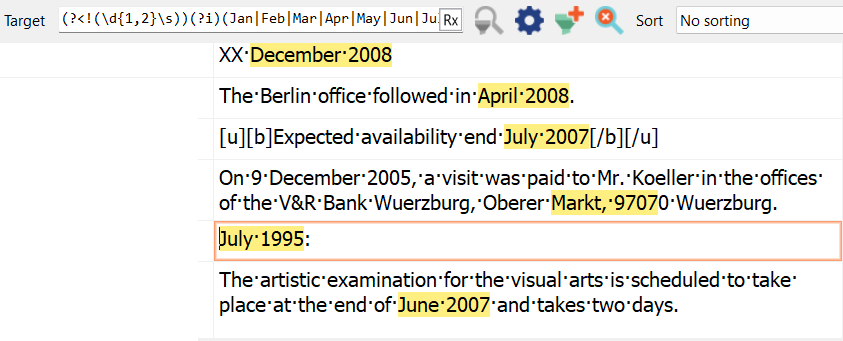
See the two false positives? The first with “XX” as a placeholder for the day, and the second involving a German address. Both can be dealt with by modifying the filtering expression. If you know there might a placeholders like “XX”, include that in the negative lookbehind: (?<!((\d{1,2}|XX)\s))
The German postal codes have 5 digits, so adding a word boundary (\b) after the 4-digit number will fix that second false positive.
But for visual screening in the memoQ translation and editing grid, all that extra foolery is unlikely to be necessary. It’s good enough for me in most cases to have a crude expression that will narrow hundreds or thousands of segments down to a dozen or so I can scan quickly with my eyes.
What about <day> + <month> dates without years? Much like the last example, except with a scary old negative lookahead to exclude the year.
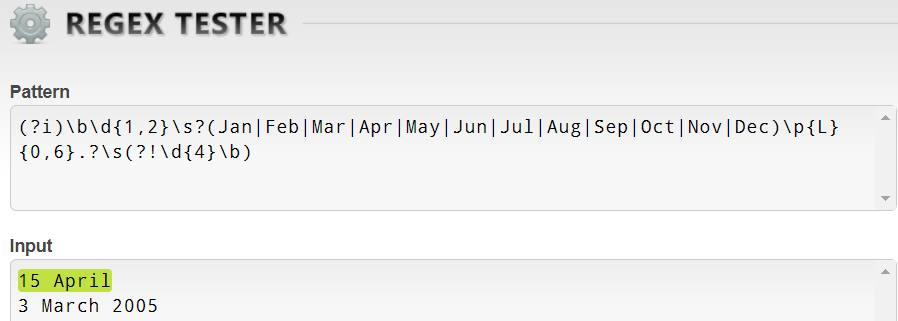
For UK dates, with a little idiot-proofing, perhaps:
(?i)\b\d{1,2}\s?(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\p{L}{0,6}.?\s(?!\d{4}\b)
My favorite .NET regex test page tells me it works:
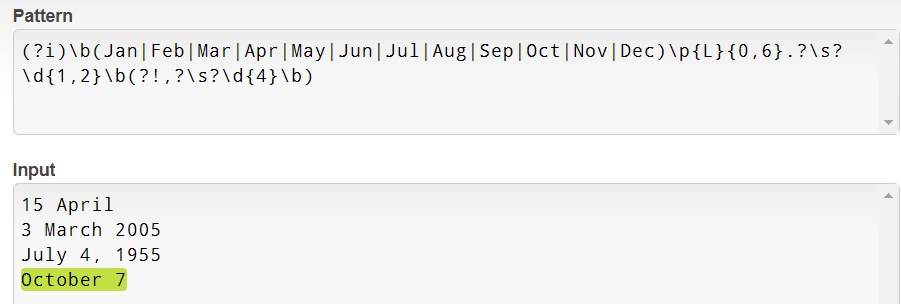
And what about the same thing, but with a US flavor? Just a small rearranged variant:
(?i)\b(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\p{L}{0,6}.?\s\d{1,2}(?!\d{4}\b)
Looks promising on the test page:
But checking against my test TM…

I can see that a little more work might be needed. I’ll leave that as a character-building exercise for the student for now, and we can talk about it in the comments or a future thread, chat or live session if that’s important to anyone.
I can’t emphasize enough how important it is to test your expressions against large datasets like translation memories with a lot of past work in them. Almost inevitably there will be surprises to learn from. It is good to know the limits of your toolkit.
And if you aren’t completely freaked out yet, I should probably mention that we forgot all about dates like June 16th, 1966. There are a number of ways that the expressions presented in this article can be adapted to this and other variations; examples of relevant regex can be found in some of the auto-translation rule examples in last month’s article about English dates. You can also take examples for filtering full dates from there, but you’ll need to substitute lists like those in this article where translation pair groups are used in the auto-translation rules.
If you’ve sat in on memoQ’s webinars discussing regular expressions or attended a workshop of a few hours or days somewhere, you may have already encountered examples of regular expressions used with dates. But these were likely much simpler than the examples I have presented here and elsewhere. The real world of translation is mostly far more complex than any workshop day can encompass for subjects like this, and it takes a lot of time, practice and painful mistakes before anyone learns to anticipate the likely cases for which you’ll need to have expression tools to help you reliably. It took me years to get there, and I still usually need several rounds to get things right.
Those who want to go deeper into this and related subjects will have that opportunity in discussions which are part of the upcoming Regex Assistant course. The main focus of the course will not be regex syntax, because I’m opposed to inflicting such abominations on the average intelligent colleague, but masochists will have an opportunity to “go there” with some guidance in special sessions or discussion spaces if so inclined.
And for those who want them, a downloadable collection of most of the regexes in this article is linked below. These may serve as useful examples for creating your own collections in your working languages.
Keep reading with a 7-day free trial
Subscribe to memoQuickies Substack to keep reading this post and get 7 days of free access to the full post archives.