


Signs of trouble!
Along the road to more responsive currency rules and regexes....


Y’all like that new memoQ logo? It was inspired last night by a little coding headache I experienced with an “easy” fix to some currency auto-translation rules requested by a colleague specialized in financial translation.

The challenge appeared simple enough.
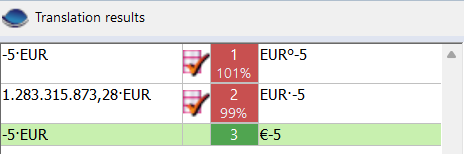
She didn’t want negative currency figures to have the negative sign between the currency code or symbol (hits
#1and#3in the screenshot below) but rather in front of the code or symbol for currency (e.g.–€5), andthe desired character for the negative sign was an en-dash (
U+2013).
Well, after thinking about the matter a bit, I realized there are probably two main cases, calling for different solutions.
Case 1: Patching up existing text
This would be necessary, for example, if a big job had just been finished, and the client expressed a desire to have the currency figures reformatted, or if one were responsible for editing one of those orgiastic messes from a trashlation whorehouse in the bulk market bog, with each of a large team of trashlators doing as they will to write the negative currency amounts.
The quickest way to deal with a mess like this in large quantities is with a Find & Replace expression set. Something like this:


Similarly, for currency symbols. Note that the dollar sign, a reserved character in regex, has to be escaped with a backslash:
However, although the regex works just fine in the Regex Assistant dialog, it fails to make corrections with a Find & Replace dialog in the translation and editing grid. This is a serious bug which has not been addressed. And you should be aware of such possibilities any time you are using regexes involving dollar sign characters in memoQ.
Now of course those Find & Replace regexes can be reformulated more generally, perhaps something like this:
Find:
(\b[A-Z]{3})\s?[\u002D|\u2212|\u2013](\d+)Replace:–$1 $2Find:
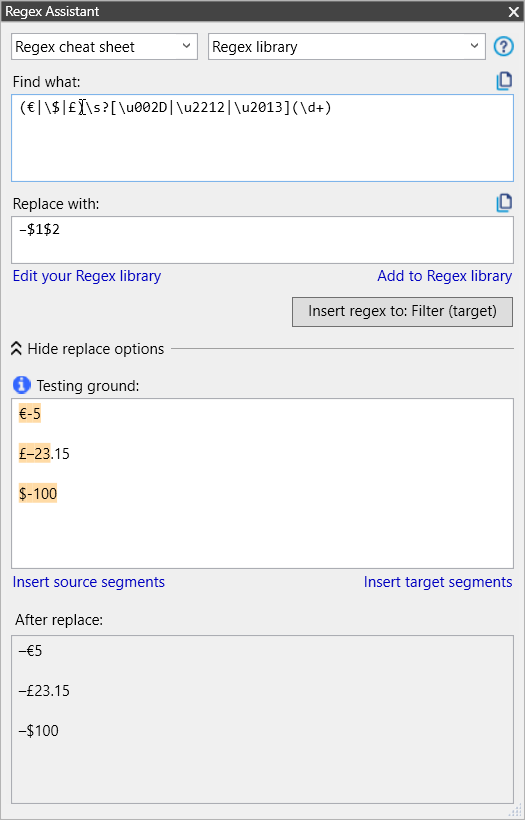
(\p{Sc})\s?[\u002D|\u2212|\u2013](\d+)Replace:–$1$2
The first Find expression uses a regex list expression for three consecutive capital letters, as currency codes are always expressed that way. The \b is a boundary to ensure that there are no other characters except possibly spaces before the three capital letters.
The second Find expression uses a Unicode character class to match currency symbols. The dollar sign is not part of that class AFAIK, or if it is, it still fails to work.
So these expressions can help you fix a large text quickly, though if you have to deal with a lot of dollar signs, you’ll have to… oh, wait a minute….



We have a gremlin in the house!
When that invisible word joiner character is removed from the text, I have to eat my words about things not working where dollar signs are involved. In fact, the class \p{Sc} also works with the dollar sign, so yes indeed I should have looked that up.
Now it’s a little embarrassing to overlook the possibility of invisible characters screwing up my regex, but I think I was primed to fail there by having encountered exactly the same problem in a number of test files I have used recently where I also failed to copy the text that mysteriously failed to work with my regex into a code point converter (see the screenshot above) to see the Unicode values of all characters present, including the invisible ones!
Stuff like this happens more often than we realize! So what should be done about that? There are lots of possible approaches, including
preprocessing routines to strip troublemaking characters like word jointers (
\u2060) and zero-width spaces (\u200b) from the source text. That can be automated, or manual, for example with a Find & Replace to replace all instances of those characters with nothing.adapting regexes to allow for their possible presence. I had to do this once for a regex to clean up badly formatted numbers in a tourist guide, where for some reason about half the phone numbers had one or more zero-width spaces embedded. Something like an optional list
[\u200b\u2060]?would do. Or:
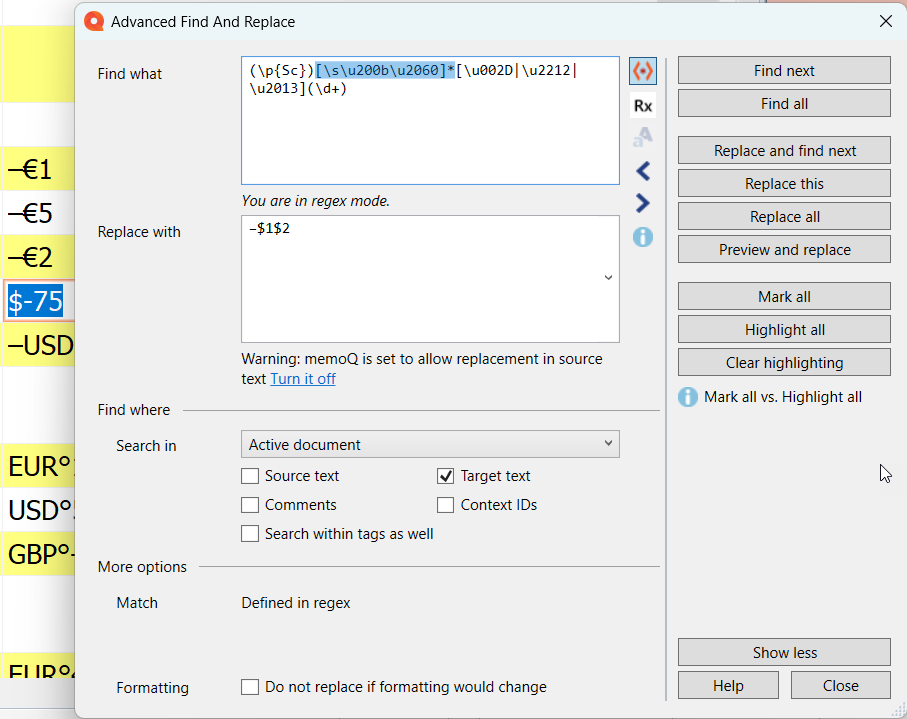
And just like that, things suddenly work!
Understand that when I talk about idiot-proofing a solution, I include myself among those idiots.
Case 2: Patching my currency auto-translation rules

This case is a good example of those quirks of the memoQ .NET regex implementation that I mention from time to time. That lovely extension with translation pairs can wreak havoc on the numbers and values of nearby groups. As far as I know, this is not officially documented, and as one experienced teacher and developer of regex for memoQ put it,

I will refrain from any remarks on corporate consulting agendas….
The starting point in my quest to replace all negative signs in an auto-translation rule for currency and to put that sign wherever I want it begins with expressions like this from rules I made perhaps 14 years ago, adapting them from the example numbers rules distributed with memoQ desktop and server installations:
(?<!(?:,|\.|\d|\d\s|\d'|\d’|\d´))([\u002D|\u2212|\u2013]?\d+)\s?
(?i)(#currencies#)
The part ([\u002D|\u2212|\u2013]?\d+) is where the negative sign (three possible characters using their Unicode values) is captured together with the first string of numbers. This is where the problem starts.
We need to split that. Changing it to ([\u002D|\u2212|\u2013])?(\d+) for example changes the group numbering and allows the captured negative sign, if present, to be put wherever you want it in the replacement regex.
But we want to map every possible negative character to an en-dash. Or at least my friend does. So we’ll do that with a translation pairs list:
(?<!(?:,|\.|\d|\d\s|\d'|\d’|\d´))(#negsigns#)?(\d+)\s?
(?i)(#currencies#)
And this is where everything goes to Hell.
When I’m working in memoQ and I see unpredictable shit like this, my available tools for tracking down the problem are limited. It helps a lot to know which group is holding what value, so for texting purposes I might write a stupid replacement regex like this:
$1 / $2 / $3 / $4 / $5 / $6 / $7 / $8 / $9 / $10 / $11 / $12
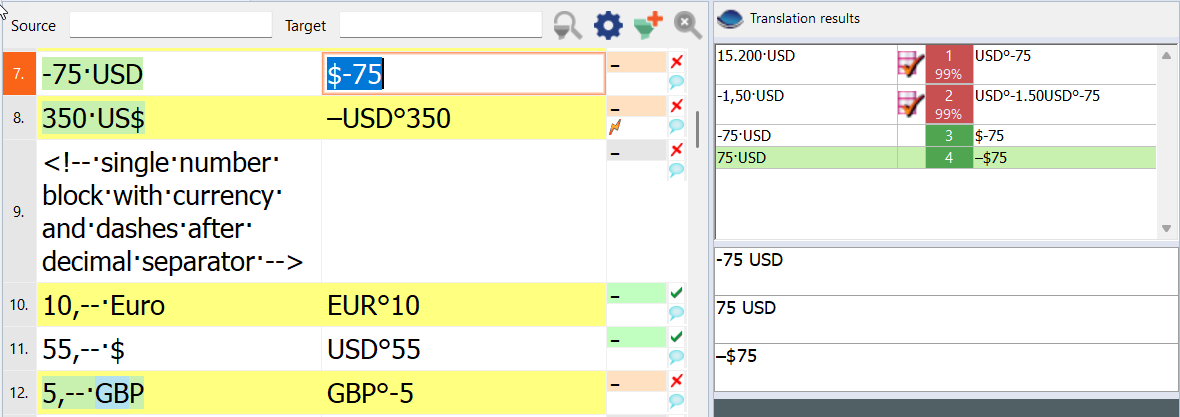
That just gives me a slash-separated list of the group values. Groups holding nothing are just output as “$X” where X is whatever number that empty group has.

There are two currency rulesets active in the screenshot above. The value in hit #3 is from one of my older working rulesets, included for reference. Notice in hit #4 that the number “75” is not present as the value in any group.
That knocked me for a loop. After trying to find a solution for over an hour, I gave up, poured myself a stiff whiskey, and went to bed. Just as I was drifting off to inner space, the thought occurred to me, “As long as the damned group is disappearing, maybe I should put in a sacrificial group for Mighty Cthulu to satisfy his hunger.” So
(?<!(?:,|\.|\d|\d\s|\d'|\d’|\d´))(#negsigns#)?(\s)?(\d+)\s?(?i)(#currencies#)
and I arrived at
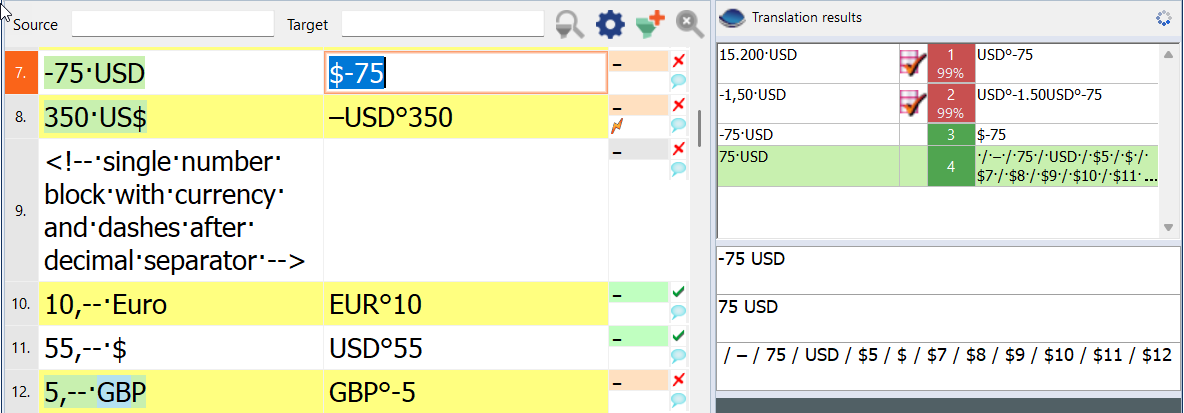
which showed the number value in the third group. Group 2 has the substituted en-dash, and Group 6 holds the substituted dollar sign I want instead of USD, so the replacement regex I would want in this case is
$2$6$3
Q.E.D.
So with less than an hour of editing, those currency rules will be in the requested form to handle the negative signs.
This was for a set of rules for transforming German currency expressions to English equivalents; I will distribute it or a similar German to English ruleset at the workshop on March 27. These rules can be adapted easily for any other target language from German sources, and that’s one of the things I’ll talk about.