

Recently, a guest post by Ana Carolina Ribeiro on the Translation Tribulations Substack discussed inclusive language. It’s a subject I care about, because I feel that social inclusion is one of those things which, when lacking, can lead to unfortunate outcomes and misunderstandings, and language is an important contributor to whether someone feels they are included in discussions. The last professional association in which I think I am still a member, IAPTI, even has a division dedicated exclusively to promoting good practice in inclusive language, which I find slightly puzzling, but applaud for the attempt to raise awareness and encourage people to choose their words with due consideration for potential readers.
But it’s also not an easy subject. Specific recommendations for implementation vary widely, and in languages such as German can be politely described as chaotic. I was always grateful in my translation work that I seldom encountered the many new forms proposed to “solve” the gender crisis in the German language.
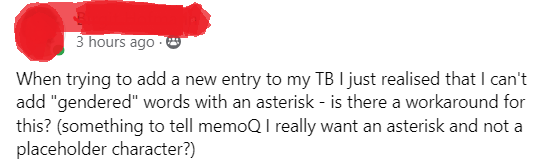
The screenshot question at the top of this article, which an experienced colleague posted in a social media forum, doesn’t begin to cover the scope of what one might encounter in German for neogendering practices in the written language. Let’s take the German word for “worker(s)” as an example: der Arbeiter / die Arbeiter. Well, that would be the singular and plural forms for male worker. The traditional feminine forms are die Arbeiterin / die Arbeiterinnen.
The texts I dealt with were generally rather sexist and just used the male form, sometimes with a declaration at the beginning that masculine forms were “inclusive” of all the myriad genders. Well, some disagree with that, and sometimes I would have fun using feminine forms and then asking innocently if those are not inclusive as well?
But the ardent language engineers on the front lines of the battle for equality soon provided us with new weapons for wordworkers (or Spracharbeiter / Spracharbeiterinnen).
If my texts did not simply default to masculine forms, I usually encountered attempts at inclusion like Arbeiter und Arbeiterinnen, which delighted me, because I usually charged texts by the source character count, and this bloated things very nicely and made me more money.
Soon, cheapskates began to write things like Arbeiter/innen to save space and perhaps some budgets. But some preferred Arbeiter/-innen. However, in that long winter of Teutonic discontent in matters of language, soon the warring tribes contended with forms like
Arbeiter_innen (“Gender-Gap)
Arbeiter:innen (“Gender-Doppelpunkt”)
Arbeiter-innen (“Gender-Pause”), and
Arbeiter*innen (the “Gender-Stern” or “Gender-Sternchen” of concern in the original question).
What do we have so far? A lucky seven options. Someone let me know in the comments if I forgot any. And let’s not worry about the dilemmas posed by vowel changes with gender! That would spoil the fun.
There are two directions from which we can approach this issue. I’m fairly sure that the person asking the question (a German) is translating into German and has chosen the Gender-Sternchen as their non-gendered language convention of choice. So I’ll deal with the into German approach first, and then the from German problem later, into English since that’s my thing.
Into German
I don’t know if they go in for the gendering contortions with articles in singular cases like der*die Ärtz*in (oops, that ugly gendered vowel change rears its head!), so I’m going to ignore that for now. We can hash it out in the comments if it’s important to anyone.
The best approach is an auto-translation ruleset. You can whine all you like about how the memoQ term base model should be adopted to comply with all the myriad gendering conventions, but I’ll be happy to bet against that happening in our lifetimes. It’s not likely to be a high priority for many customers using the translation management system, and if it is, auto-translation rules provide an adequate workaround. If my prediction is wrong, the beer’s on me as we celebrate. Or coffee if that’s your preference.
There are possible variations on that auto-translation scheme. The simplest involves a translation pair list with the term in the source language and the root of the “gendered” form in German in the target. I’ll use English as the source language in my examples, but if the source language is “non-gendered” Spanish, for example, the problem really isn’t much more complicated.
Whether you match singular forms in the source with singular forms in the target and plural with plural is another question. In my own work I have often found it necessary to change the numbering of nouns in translation, so I usually structure my term bases and auto-translation rules in a permissive way to allow that. Many approaches are possible; I’ll go with the simplest one here (my usual approach), and if someone has use cases for which more complexity is needed, we can talk about that.
So you’ll have a translation pairs list that looks something like this:
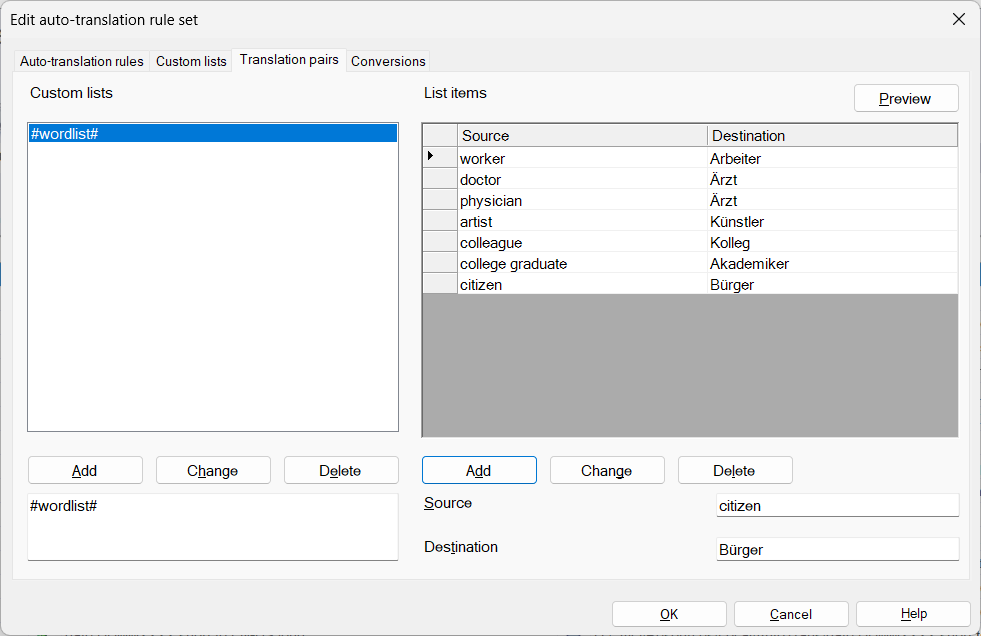
The match rule for the source text is simple, though you may want to consider whether word boundaries (\b) are needed to handle cases of compound words, or to distinguish singular forms from plurals. For this example, I’ll assume not. So the match rule is just
(#wordlist#)
and the replacement rule would be
$1*in
to offer the singular form. If used in QA, this would accept the plural form ending with -innen as well. So my habit of changing plurals to singular forms and vice versa as style demands would be accepted.
If you need to distinguish singular and plural forms and match them with their like in QA, then two rules are needed (or possibly more to accommodate special cases):
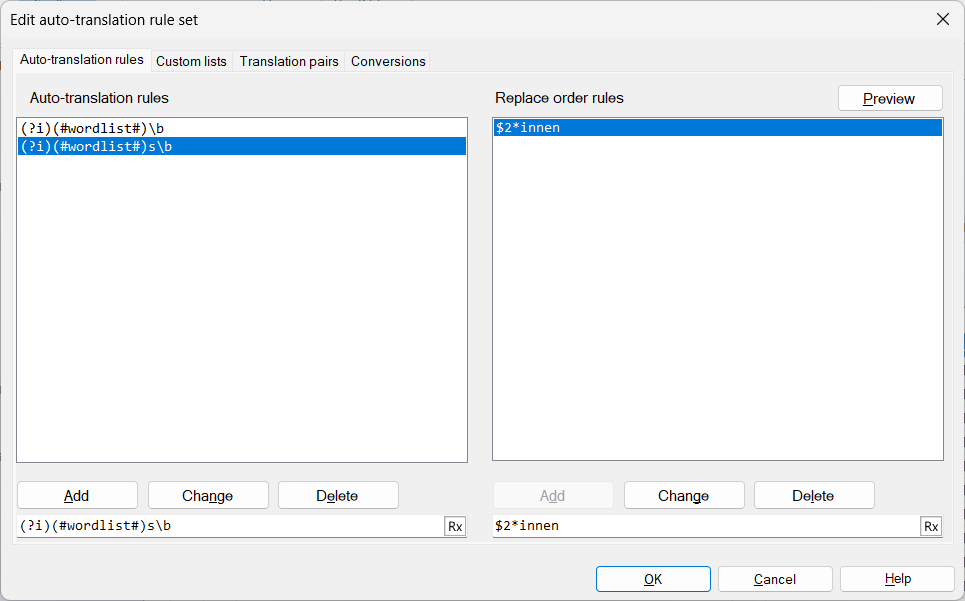
singular
(?i)(#wordlist#)\b
with the replacement rule
$2*in
and
plural
(?i)(#wordlist#)s\b
with a replacement rule of
$2*innen
Huh? Why did I suddenly change from Group 1 ($1) to Group 2 ($2) in the replacement rules? It’s because I decided to use the (?i) switch to make the rule insensitive to case, and even though that isn’t supposed to be counted as a group in .NET regex, in these cases the somewhat non-compliant regex implementation by memoQ does just that.
So the ruleset to handle singular and plural forms separately would look something like this:
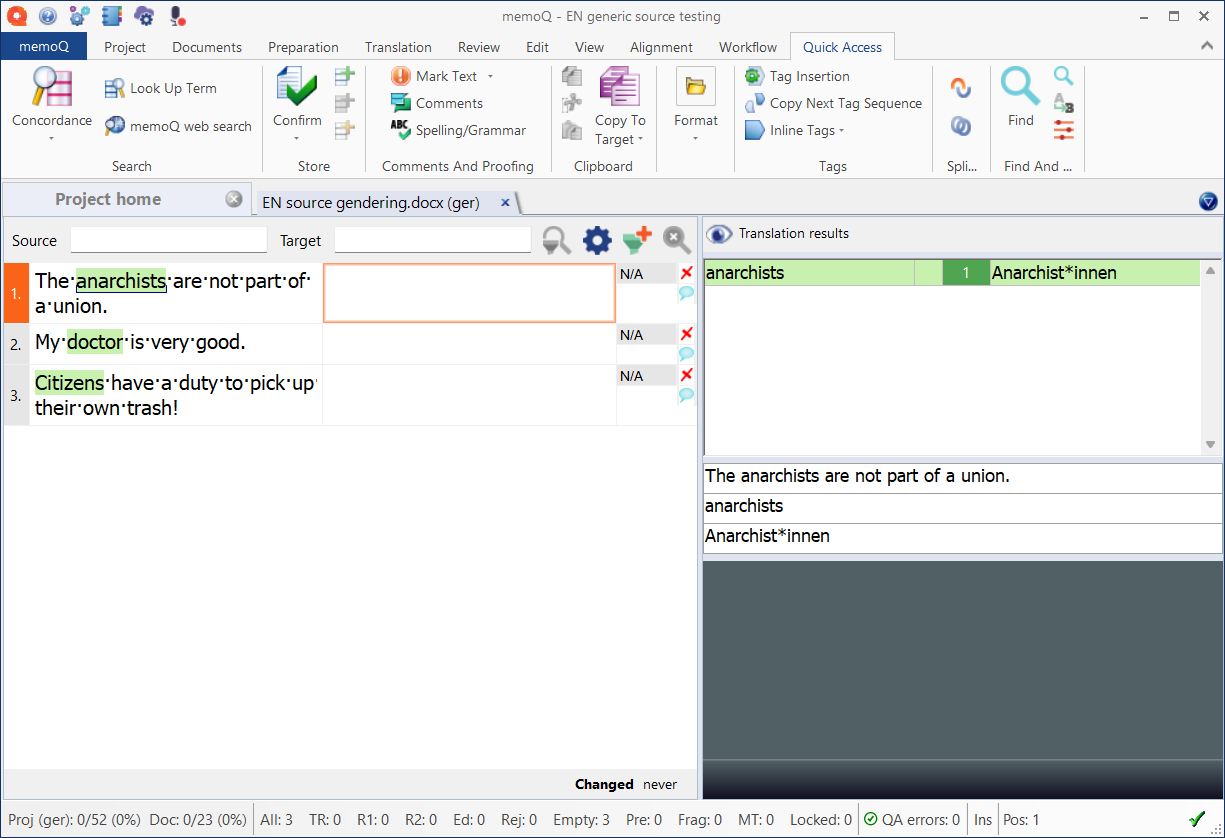
In the translation and editing grid, you’ll see green hits in the Translation results pane with the desired forms:
From German or inspecting German
If I’m looking at a “non-gendered” source text to translate into another language, I would probably want to get an overview of the forms that occur. I might want to do the same to a target text where I was supposed to apply rules like those described for translating into German. An easy way to get this overview is to use a regular expression to filter the segments and show only those where some form of non-gendered language occurs.
As a trial expression for filtering, I’ll use
\p{L}+(In|((\*|:|/?-|/|_)(?i)in))(nen)?
which covers seven cases other than writing out the masculine and feminine forms (Beidnennung). Yeah, I forgot to count one earlier. This chaos can be confusing.
The regular expression here can also be used to ensure that a team of German authors have stuck to the style guide and not gone various ways with each following a personally preferred convention.
If you are writing rules to take non-gendered German forms and map them to non-gendered forms in some other language, the crazy lists used in this example may also give you guidance in how to construct rules that will allow various conventions to be handled by a single rule.
Oh, but I didn’t explain the regex! That’s on purpose. For those who care about syntax, I leave it as a student exercise to puzzle out for now. Why did I put the case sensitivity switch exactly where I did? An interesting question perhaps. For the normal rest of you, I’ll just suggest copying the expression to your Regex Assistant library for future reference.
Thanks for that. I'm still working out a regex-based approach in Trados (other than a QA routine using non-inclusive and inclusive variants in a Termbase).