


LiveDocs corpora: settings resources
How to fine-tune your LiveDocs match behaviors


LiveDocs settings
Did you know that it’s possible to customize the match behavior of your bilingual LiveDocs corpus content? And that your custom settings can be
- applied generally to all new corpora,
- set for all corpora in a particular project,
- or customized for each individual corpus in a project?
The default corpus settings in memoQ kinda suck for the way I work personally. Customizing these settings in fit-for-purpose configurations allows you to
- establish the minimum threshold for showing Translation results matches
- define the “good” match percentage for pre-translation
- set match penalties for particular users and corpora
- set match penalties for alignment link type (confirmed or not, auto, manual)
- set match penalties according to segment status in bilingual document
- set match penalties for keywords that are applied or not to corpus documents
- set match penalties for sublanguage differences for the source or target
- set match penalties based on the date a segment was last changed
Managing LiveDocs settings
LiveDocs settings follow the typical scheme for memoQ light resources. They can be created, imported, exported to shareable *.mqres files, edited and deleted in any of the three usual places:
The Resource Console, a top-level place for all these operations, which will not affect default LiveDocs settings assignments nor settings applied within any project, though edits made will affect how resources set in the Options or within projects behave. LiveDocs settings can also be published to a memoQ TMS server here, which is not possible from other locations (Options or individual projects).
The memoQ Options (for new project defaults)
Project Settings. Specific LiveDocs settings which differ from a project’s defaults can also be assigned to individual corpora via Project home > LiveDocs > (individual corpus) > Settings.
Edit LiveDocs (corpus) settings dialog
The first two options on the Match thresholds and penalties tab specify the minimum level to be considered a “match” or a “good” match. These values are applied for pre-translation, and the first value (minimum) controls whether a match is shown in the Translation results pane.
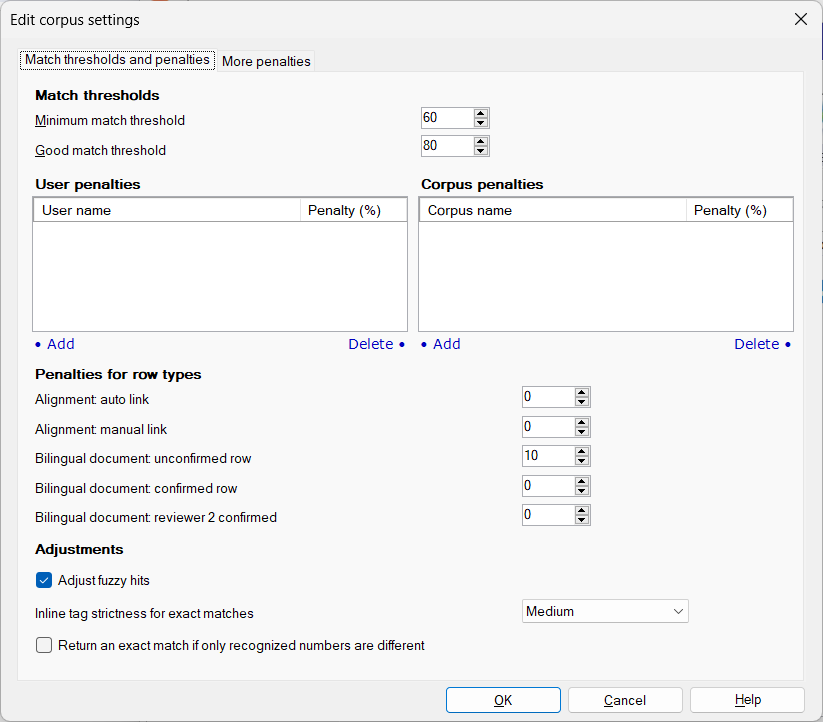
In the example shown here, the default of 95% for a “good” match has been changed to 80%, which is generally more helpful for pre-translation.
Penalties applied for specific users or corpora can be used to control precedence of content in the corpora to which the settings are applied. For example, if a 5% penalty is applied, a 100% match would be reduced to 95%, and a match with a higher value from another source (a translation memory or a corpus match without that penalty) will be used preferentially.
In my own work, I don’t penalize auto-aligned segments (the default is 5%), but I do penalize an unfinished alignment (see the screenshot below). My assumption is that if I have marked the alignment as finished, I have verified that everything is correct as far as I can tell. Those with nagging doubts about alignments could leave the default auto-alignment penalty or adjust it to some other value (manual links have been personally confirmed and should be OK), so even if an alignment is carelessly marked as finished, there will be a mechanism for calling attention to apparent matches which haven’t been personally inspected.

The options on the second tab (More penalties) are fairly self-evident. In the example above you see my penalty choice for unfinished alignments. Not marking alignments of documents provided by a customer as unfinished and applying a suitable penalty can
serve as additional insurance that errors overlooked during alignment will not end up as 100% matches of 101% context matches and ensure additional inspection by the translator,
the additional work involved in quality verification of legacy translations can be offset this way where discount grids are applied for matches, and
if translator compensation is influenced match rates, this avoids harming that service provider by uncompensated effort for cleaning up garbage. A similar approach using metadata or specific resource names for TMs and corpora can complete this strategy of fair compensation if well considered.
A good choice of keywords assigned to documents saved in a corpus can be used to influence the match rating of those documents. If you opt for generic language settings at the project level to avoid possible “missing” content, keywords indicating language variants can be used to ensure that otherwise equal matches will give preference to the match marked for the desired language variant (Indian versus American English, for example).
If heavy penalties are assigned to LiveDocs content based on any criteria, the matches may be excluded from display in the Translation results pane, but they remain accessible for reference in concordance searches.