


Digital object identifiers
Tag, they're it! And checking your research references....


The question of dealing with digital object identifiers (DOIs) is an interesting one that is relevant to a lot of translators of scientific and medical articles. The person posing that question on social media wanted to protect the structure of the DOI reference by converting it to a protected tag in the translation workspace (memoQ in this case), and after translation, that tag would revert to the text constituting the reference.
But there may be a few other things of interest for DOIs in a text for translation.
First of all, one might wish to determine the presence of DOIs in a text and verify that they are the same in the source and target text. In some cases, one might want to look at translation memory records to see if they have been handled correctly in the past. (Doing this with trashlation memories from LSPs can be a revealing exercise.)
So some kind of filtering regexes might be a good place to start. Maybe also auto-translation rules that can be used for translation and editing as well as QA. And maybe some checks on the Regex tab of QA profiles. And of course a Regex Tagger configuration that can be run in the translation and editing grid or chained in a cascading filter to tag the DOIs when a document is imported.
Befotre tackling all those tasks, however, I should bring myself up to date on the ways in which a DOI might be encountered in a text. A little research showed that the Facebook post covered just one of many possibilities. Examples I found included:
doi:10.1080/02626667.2018.1560449
https://doi.org/10.1111/hex.12487
https://dx.doi.org/10.1080/02626667.2018.1560449
https://doi.org/10.1016/j.jpsychires.2017.11.014J Med Internet Res. 2023; 25: e49019.
Published online 2023 Nov 13. doi: 10.2196/49019doi: 10.21037/mhealth-20-121
10.1093/ajae/aaq063
10.1371/journal.pgen.1001111Baozhuang Niu, Jian Dong, Zhipeng Dai, Jimmy Yong Jin, Market expansion vs. intensified competition: Overseas supplier’s adoption of blockchain in a cross-border agricultural supply chain, Electronic Commerce Research and Applications, 10.1016/j.elerap.2021.101113, 51, (101113), (2022).
So let’s go with those for a start… we’ll assume for now that no reformatting is desired.
The example “doi: 10.21037/mhealth-20-121” suggests that perhaps the questioner was wrong to state that a DOI starts with 10.dddd/ because there are five digits in this example, not four (which we see in the other examples). Is this correct?
The Wikipedia page for Digital object identifier states
The prefix usually takes the form
10.NNNN, whereNNNNis a number greater than or equal to1000, whose limit depends only on the total number of registrants.[12][13] The prefix may be further subdivided with periods, like10.NNNN.N
Later in the article this reference occurs:
Levine, John R. (2015). "Assigning Digital Object Identifiers to RFCs § DOIs for RFCs". IAB. doi:10.17487/rfc7669
so it would appear that we might indeed have more than four digits. There is an ISO standard for DOIs, but I’m not going to buy the standard just to produce a standards-compliant working solution without due compensation. So I’ll make some assumptions here and hope they fit the actual standard.
The examples of DOIs I have found so far show the following:
“
10.” possibly preceded by a number of optional stringsFour or more digits thereafter, followed by a forward slash, followed by
A string comprised of lower case letter, numbers and certain symbols (
/-.)A final alphanumeric character
Let’s consider first what might precede the “10.”
I think the following regex list should cover that:
(https://(dx.)?doi.org/|doi:\s*)

Hmm… so far so good. But that first part is optional, so let’s go a little farther:
(https://(dx\.)?doi.org/|doi:\s*)?10\.

That’s a little better. On to points #2-4 then. I’m not going to make any assumptions about the number of digits after “10\.” (yes, I’m escaping those periods so they aren’t understood as “any character”, very anal retentive of me and not really necessary) until I see the ISO specification, so:
(https://(dx\.)?doi.org/|doi:\s*)?10\.[\d]+/[\da-z\./-]+[a-z\d]
Hmmm… looks like we’re in business:

Now if there are any capitalization issues, you can stick a (?i) at the front of that regex and all will be well. That switches off case sensitivity. What the hell, let’s do it now:
(?i)(https://(dx\.)?doi.org/|doi:\s*)?10\.[\d]+/[\da-z\./-]+[a-z\d]
Users of other CAT tools: this is your lucky day so far, since this regex will work in any environment. But after this point, memoQ users will have all the fun.
memoQ users: you might want to stick that expression in your Regex Assistant library now.
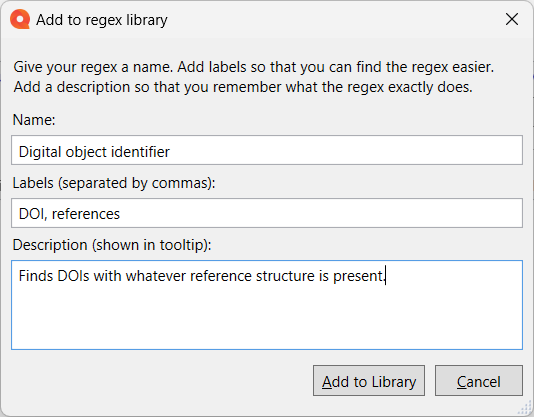
So… the questioner wanted to tag those structures, right? Then let’s go here on the Preparation ribbon above the translation and editing grid:


Using the button for the Regex Assistant, I retrieved the expression from my library and added it. But oh no! I see that part of the URL in one example wasn’t captured! No problem. I don’t know if that’s an error or not, but I’ll make the “s” optional:
(?i)(https?://(dx\.)?doi.org/|doi:\s*)?10\.[\d]+/[\da-z\./-]+[a-z\d]
and we’re OK:

Don’t forget to update that in your Regex Assistant library!


And be sure to save that Regex Tagger configuration so you can use it to build a cascading filter and tag all those DOIs on import next time! The saved configuration will be found with your filters in the Resource Console:

So now the DOIs are tagged:

Assuming that you want no changes in the captured DOI string, building an auto-translation rule is rather simple. Just take the saved expression from you library and use $0 for the replacement.

Here’s what that rule would look like in the translation and editing grid without tagging:

And of course you can use that for QA checks by enabling the auto-translation rule checking on the first tab of your active QA profile.
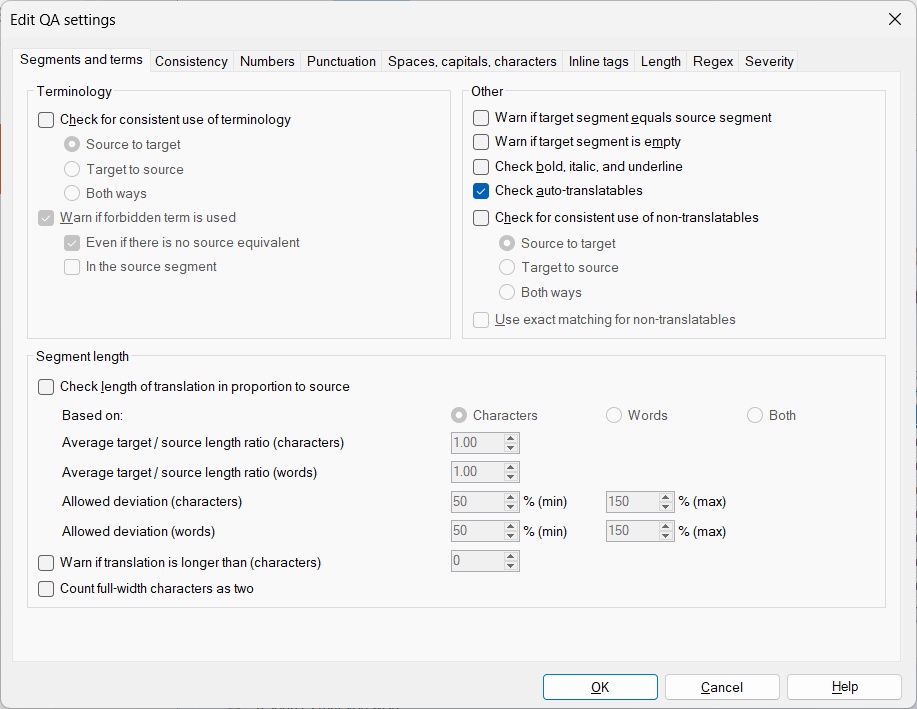
This would also cause the “lightning” icon warning to be displayed in the translation and editing grid if a confirmed segment has a DOI transcription error in the target:

You could also configure the DOI check on the Regex tab of a QA profile:
