

Tag! That's it with REGEX
Tag! That's it with REGEX
Protecting text you shouldn't mess up in translation


One advantage of a good translation environment tool (TEnT) is that it enables many different types of files to be translated safely — by exposing the text to translate while protecting important formatting elements.
Take HTML files, for example. These have been a mainstay of the World Wide Web since it was called that, and today’s internet, intranets and extranets still have quite a lot of HTML.
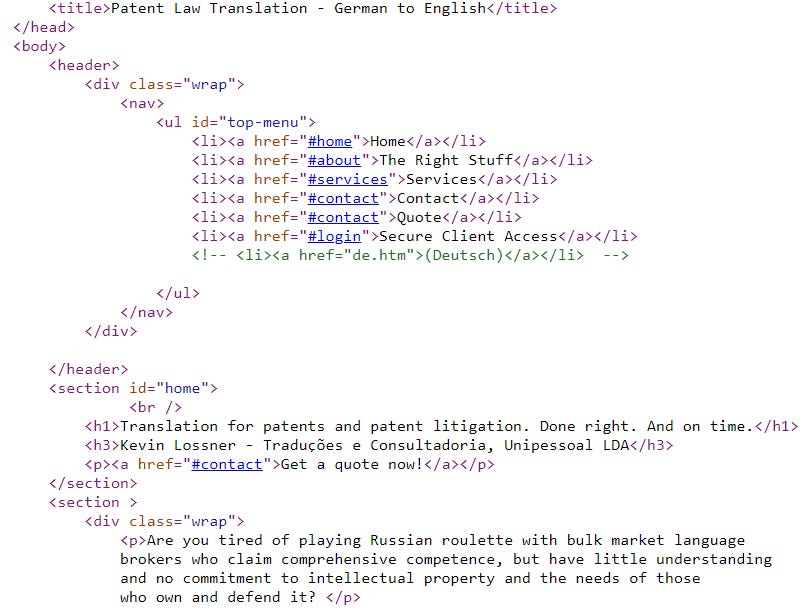
Text with hypertext markup language (HTML) can appear in many forms. You’ll not only find it in files with extensions like *.html, *.xhtml, *.htm or *.asp but often in simple text files or in Microsoft Excel spreadsheets, for example. HTML tags in text files, spreadsheets or other file types are often not interpreted as expected, leaving these tags vulnerable to being overwritten and damaged, or omitted entirely, with unfortunate consequences for the page format.

The HTML import filter hides many of the tags (the external ones that occur outside of sentence or text chunk boundaries), and inline tags are protected in a way that prevents the translator from mistyping them and which allows for some good automated quality checking after translation to ensure that all tags are present and in their proper places.

Now there’s a lot to unpack in the example in that last screenshot, which I’ll do shortly in a follow-up post, but for now just notice that in this text imported from an *.xslx file, the HTML tags are completely unprotected. And the segmentation is different too, a consequence of the particular filter chosen for the import. In older versions of memoQ, the simple solution for recent versions (such as memoQ 10.6) isn’t available without some hacking that most people will find just a little too scary, but another post will deal with all that. For now, let’s just do something about those unprotected tags, because errors in reproducing them on the target text side could have dire consequences with the text formatting and possibly even the function of the web page after translation.
The Regex Tagger to the rescue!
The online memoQ Help has a rather good overview of this feature. The Regex Tagger can be used in two ways to
protect non-translatable structures in an already imported document by converting these to inline tags. If this is done in the working memoQ grid, don't forget to save the instructions you use for tagging so you can re-use them later!
Provide inline tagging of content during import as a sequential operation in a cascading filter. The regular expressions to be used in the Regex Tagger configuration can be entered directly in the filter cascade, or the empty settings can be substituted by a saved configuration using the Filter configuration drop-down menu in the dialog for selecting the Reteg Tagger filter as the one to “chain” (follow after the prior filter in the cascade):
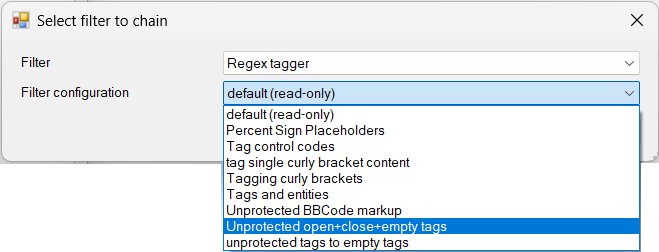
A few of examples of Regex Tagger configurations can be downloaded from the button link at the bottom of this article:
protecting
<exposed tags>protecting
[exposed BBcode]protecting
{curly quoted content}
Here’s what the markup in the second example looks like after re-importing it with the Regex Tagger configuration selected in the cascading filter dialog above:

Now those tags are no longer exposed, and they will be included, for example, in a QA check if the appropriate options are selected on the Inline tags tab of the active QA profile in a project.
Keep reading with a 7-day free trial
Subscribe to memoQuickies Substack to keep reading this post and get 7 days of free access to the full post archives.