

Importing bilingual tables to a TM
Importing bilingual tables to a TM
Many ways to go, some more sensible than others

I’ve seen questions like this so many times, and so many times the answers I see are unnecessarily complicated for the situation. And too often, in responding to such a question, the ones providing suggestions are distracted by irrelevancies and possibly false assumptions of the questioner.
The essence of the question is highlighted in the text. (I copied it from a social media platform into Microsoft Word just so I could do the discontinuous highlighting.) And the answer would apply to pretty much any translation environment tool I’ve seen. The rest is of no importance, just opportunities for some to end up in some strange solution space in a dimension of little practical use.
Someone has a two-column table in a word processing file. The table may actually have more than two columns, but what is important is that one of these columns contains a Language A, and the other column contains the translation of the first column into Language B in the same row. Something like this:

or this:
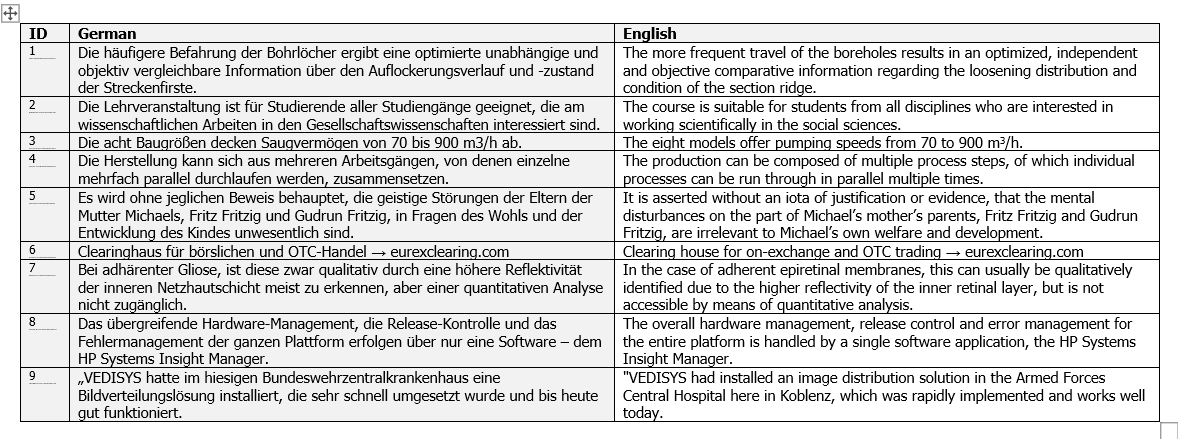
Now how would you get data like that into a translation memory?
Before you start going wild with notions of saving the source and target columns in separate files, or even transferring the data to Excel, consider for a moment that most translation memory systems can import delimited text files. Does that information change the approach you would take?
It should. Microsoft Word (and other word processing applications) can convert tables to text, typically tab-delimited text. So do that:
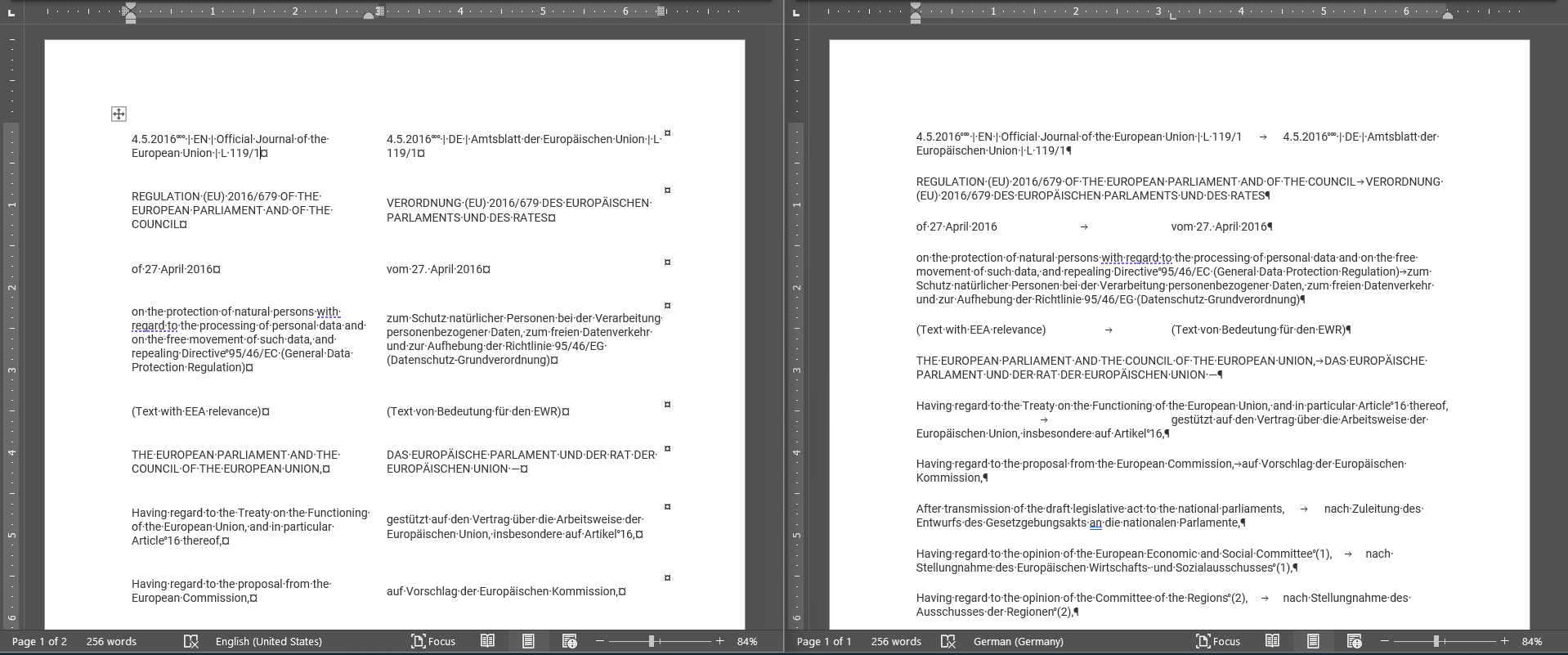
And then import the tab-delimited text to your translation memory:
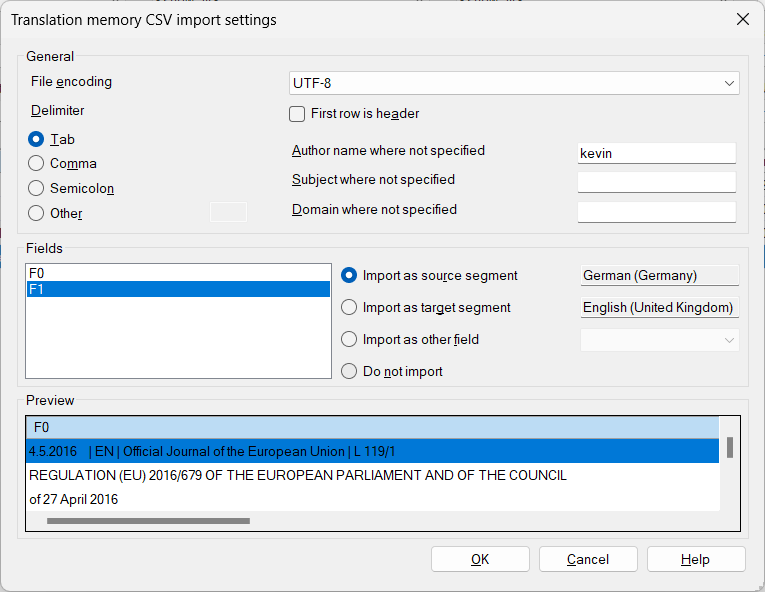
And here’s the result in the memoQ TM editor, though of course this approach would work with nearly any other translation workspace tool:
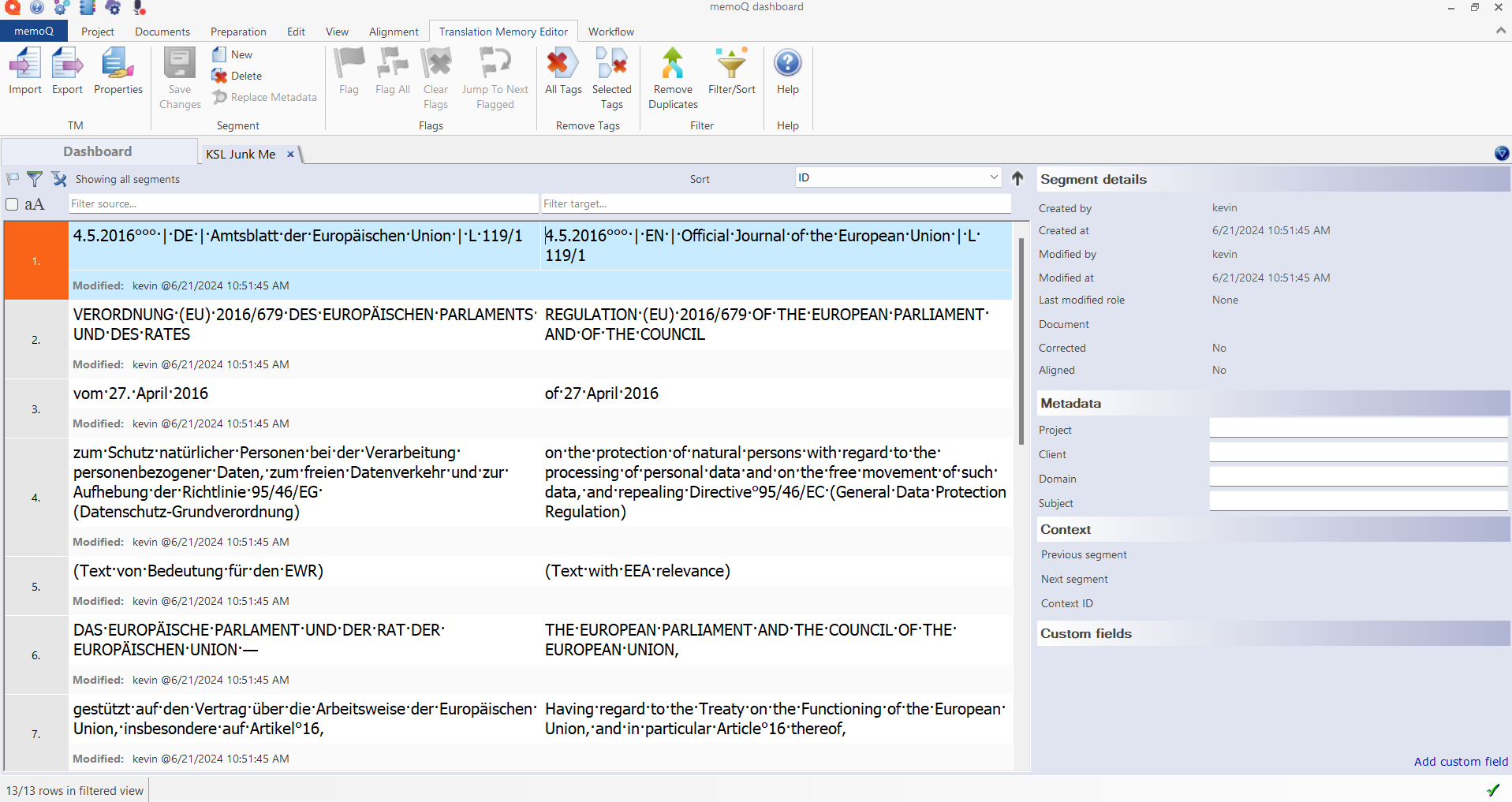
Of course there are situations where certain formatting in the table may require additional preprocessing (deleting columns, dealing with multiple paragraphs in cells, etc.) but for the case of a table export for review from an application like Trados Studio, Fluency or others with sentence-level segmentation comprising the table cells, it will work without trouble. If you are a memoQ user receiving a memoQ RTF bilingual table export, you can simply import this to a project, attach the translation memory to which you want to write the content as the Working memory, and then confirm all the segments again to write them to that TM.
Users of translation environments other than memoQ can use this approach of saving to delimited text (after deleting the header and the ID column) to get memoQ RTF bilinguals (or any other tool’s table exports) into their tool’s TMs.
Or just go here
https://porkopek.github.io/Multisearch/#/align-texts
paste the source text, paste the target text, click Align and you have the TMX ready to export in seconds
Thank you Kevin for your detailed explanation.
What you mentioned pertains more to a special case, whereas another scenario is:
The same document contains the entire source text followed by the entire translation.
In this case, you can easily split the source text and translation into two separate documents by copying and pasting, and then align them for import into the TM. The reason for aligning is to enable post-alignment editing, such as checking and adjusting segment alignment quality by splitting or merging segments as needed. memoQ's LiveDocs supports aligning document pairs, which can function similarly to a TM. However, automatic alignment is usually not 100% accurate and still requires manual editing based on the actual content. Of course, this is not the main focus of the current discussion.
The same document contains a paragraph of the source text followed by a paragraph of the translation (arranged side-by-side or top-bottom).
Here, we are referring to paragraphs, not segments. The specific formats could be:
First paragraph of the source text - First paragraph of the translation
......
Nth paragraph of the source text - Nth paragraph of the translation
Or:
First paragraph of the source text
First paragraph of the translation
......
Nth paragraph of the source text
Nth paragraph of the translation
How should this text format be handled? Before importing into the TM, segments are usually aligned, whereas the original document is aligned by paragraphs. There may even be cases where paragraph alignment intersects with alignments of several paragraphs. The method you mentioned doesn't seem to directly address such a situation; at the very least, it requires converting paragraph alignment into segment alignment (how would that be achieved?).
If the alignment feature supports importing a single document with bilingual texts, it would be similar to aligning two documents. The source text and translation could be automatically split into segments (automatic splitting isn't 100% accurate) and then checked, edited, and modified in the alignment editor. This method is more intuitive and aligns with the existing experience of most CAT tool users.